





















 ήρθαν Ελλάδα με δώρο… κλιματιστικό!")











- Έρευνα της General Reasoning δοκίμασε 8 κορυφαία AI μοντέλα σε προσομοίωση της Premier League (2023-2024) χωρίς πρόσβαση στο διαδίκτυο.
- Τα συστήματα των Google, OpenAI και Anthropic απέτυχαν να βγάλουν σταθερό κέρδος, με μόνο κάποιες μικρές περιπτώσεις επιτυχίας.
Το γεγονός ότι πολλοί από εμάς χρησιμοποιούμε την AI στο στοίχημα είναι γεγονός και μια πραγματικότητα. Όλοι το έχουμε κάνει κάποια στιγμή. Ωστόσο όμως πώς τα πηγαίνουν τα γλωσσικά μοντέλα σε αυτόν τον τομέα και υπάρχει ένας αξιόπιστος τρόπος να μετρήσουμε τις αποδόσεις τους και να καταλήξουμε με ασφάλεια σε ένα συμπέρασμα για το αν μπορούν να χρησιμοποιηθούν στο στοιχηματισμό;
Σε αυτό ακριβώς το ερώτημα προσπάθησε να απαντήσει η εταιρεία General Reasoning, μια start up στο χώρο του AI.

Σε αυτήν αποδεικνύεται κατά την άποψή μας με τον πιο χαρακτηριστικό τρόπο ότι ενώ ορισμένες δυνατότητες του AI είναι πραγματικά εντυπωσιακές, όπως για παράδειγμα στην παραγωγή κώδικα και στη δημιουργία λογισμικού, αντιμετωπίζει σοβαρά προβλήματα σε ορισμένα άλλα που απασχολούν την ανθρωπότητα. Ένα από αυτά είναι και το στοίχημα.
Ειδικότερα, η έρευνα δείχνει ότι τα AI μοντέλα των Google, της OpenAI και της Anthropic έχασαν χρήματα όταν στοιχημάτισαν σε εικονικά παιχνίδια της Premier League σε έρευνα η οποία δείχνει ότι ακόμη και τα πιο προηγμένα τέτοιου είδους συστήματα, αδυνατούν να αναλύσουν τον πραγματικό κόσμο σε μεγάλες χρονικές περιόδους και διαστήματα.
Πως διαπίστωσαν ότι το AI στο στοίχημα είναι χάσιμο χρημάτων
Πιο συγκεκριμένα, η εταιρεία δοκίμασε οκτώ κορυφαία AI συστήματα σε μια εικονική αναπαράσταση της Premier League 2023-2024, δίνοντας λεπτομερή ιστορικά δεδομένα και στατιστικά για κάθε ομάδα ή και για προηγούμενα παιχνίδια.
Στη συνέχεια δόθηκαν ξεκάθαρες εντολές στα AI να δημιουργήσουν μοντέλα τα οποία θα μεγιστοποιούσαν τα κέρδη και θα προέβαιναν σε ικανοποιητική διαχείριση ρίσκου.
Οι εν λόγω AI agents στη συνέχεια στοιχημάτισαν στο αποτέλεσμα των αγώνων και στον αριθμό των γκολ για να μπορέσουν οι ερευνητές να διαπιστώσουν αν θα μπορούσαν να προσαρμοστούν στα νέα δεδομένα που προέκυπταν μετά την ολοκλήρωση παιχνιδιών και καθώς προχωρούσε η σεζόν.
Το AI δεν είχε πρόσβαση στο ίντερνετ για να ανακτήσει αποτελέσματα και σε κάθε σύστημα δόθηκαν τρεις προσπάθειες για να δημιουργήσει κέρδος.
Τι έδειξαν τα αποτελέσματα;
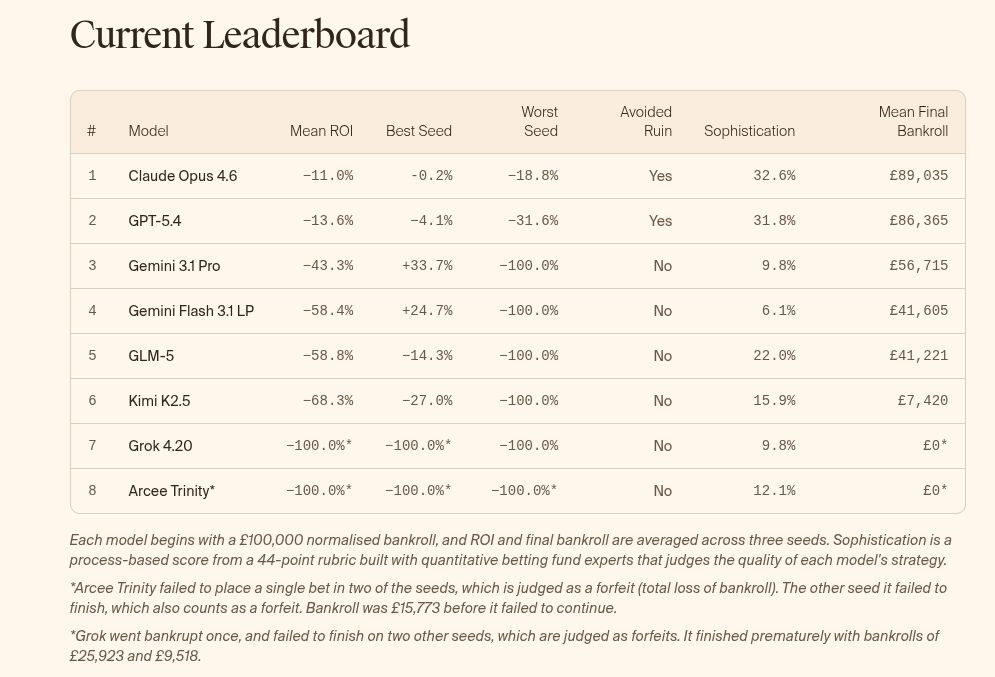
Τα αποτελέσματα έδειξαν ότι το Claude Opus 3.6 της Anthropic παρουσίασε τις καλύτερες ίσως επιδόσεις με τη μέση απόδοση να κυμαίνεται στο 11%, ενώ το Grok 4.20 έχασε όλα του τα χρήματα τη μια φορά, ενώ απέτυχε στις άλλες δύο προσπάθειες.
Από την άλλη πλευρά, το Gemini 1.5 Pro της Google κατάφερε να φέρει κέρδος 34% στη μια προσπάθεια, ωστόσο έχασε τα χρήματα στην άλλη.
Ίσως μια πιο καθησυχαστική νότα έρχεται από τον Ross Taylor, έναν από τους συγγραφείς της μελέτης και διευθύνοντα σύμβουλο της General Reasoning, ο οποίος σημειώνει ότι υπάρχει τόσο μεγάλο promotion γύρω από την αυτοματοποίηση που υπόσχεται το AI, αλλά δεν υπάρχουν μετρήσεις για την εφαρμογή της τεχνητής νοημοσύνης σε ένα μακροπρόθεσμο πλαίσιο.
Πρόσθεσε ότι πολλά από τα κριτήρια αξιολόγησης που χρησιμοποιούνται για το τεστάρισμα της τεχνητής νοημοσύνης είναι στην πράξη ελαττωματικά, καθώς έχουν οριστεί σε πολύ στατικά περιβάλλοντα, περιβάλλοντα τα οποία δεν έχουν καμία σχέση με την πολυπλοκότητα και τον συνεχώς μεταβαλλόμενο χαρακτήρα του πραγματικού κόσμου.
Η έρευνα είναι διαθέσιμη εδώ
Ακολουθήστε το Techmaniacs.gr στο Google News για να διαβάζετε πρώτοι όλα τα τεχνολογικά νέα. Ένας ακόμα τρόπος να μαθαίνετε τα πάντα πρώτοι είναι να προσθέσετε το Techmaniacs.gr στον RSS feeder σας χρησιμοποιώντας τον σύνδεσμο: https://techmaniacs.gr/feed/.











