


































Ερευνητές τεχνητής νοημοσύνης από το Στάνφορντ και το Πανεπιστήμιο της Ουάσιγκτον, κατάφεραν να δημιουργήσουν και να εκπαιδεύσουν ένα μοντέλο συλλογιστικής τεχνητής νοημοσύνης (s1) με κόστος λιγότερο από $50, κάνοντας χρήση Cloud υπηρεσιών, σύμφωνα με μια ερευνητική μελέτη που δημοσίευσαν την περασμένη Παρασκευή.
Το μοντέλο της ομάδας, γνωστό και ως s1, συγκρίνεται σε απόδοση το o1 της OpenAI και του DeepSeek R1. Μάλιστα, έκαναν την σύγκριση σε δοκιμές που μετρούν την ικανότητα του μοντέλου σε μαθηματικά και κωδικοποίηση, ενώ διαθέτουν το μοντέλο s1, μαζί με τα δεδομένα και τον κώδικά που χρησιμοποίησαν για την εκπαίδευσή του, στο GitHub, για να τα κατεβάσει οποιοσδήποτε και να τα παραμετροποιήσει.
Η ομάδα αναφέρει πως δημιούργησαν εξολοκλήρου το βασικό μοντέλο μόνοι τους και στη συνέχεια το εκπαίδευσαν με τη διαδικασία της απόσταξης (distillation), μια διαδικασία που εξάγει δεδομένα από άλλες πλατφόρμες τεχνητής νοημοσύνης.
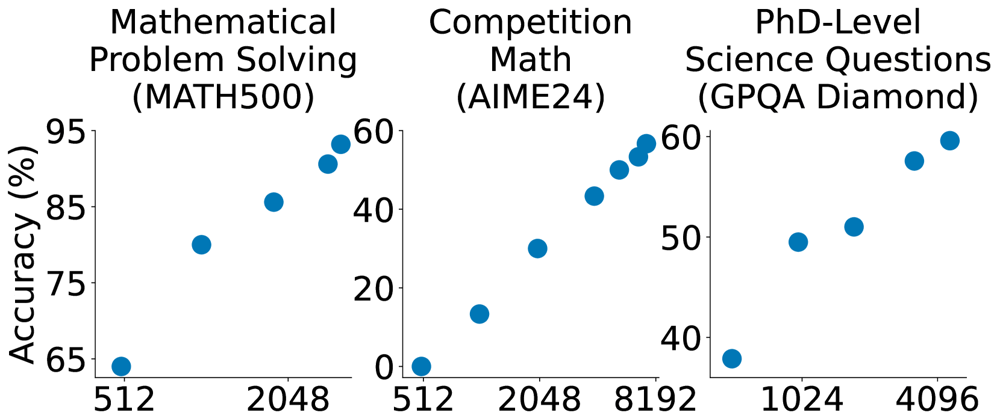
Συγκεκριμένα, δήλωσαν πως πήραν τα δεδομένα για την εκπαίδευσή του από το Gemini 2.0 Flash Thinking Experimental. Η απόσταξη είναι η ίδια προσέγγιση που χρησιμοποίησαν οι ερευνητές του Berkeley για να δημιουργήσουν ένα μοντέλο συλλογιστικής τεχνητής νοημοσύνης για περίπου 450 $ τον περασμένο μήνα.
Οι ερευνητές χρησιμοποίησαν ένα έξυπνο κόλπο για να κάνουν το s1 να ελέγξει ξανά τη δουλειά του και να παρατείνει τον χρόνο «σκέψης» του: Του είπαν να περιμένει. Η προσθήκη της λέξης «wait» κατά τη διάρκεια της συλλογιστικής του s1 βοήθησε το μοντέλο να καταλήξει σε ελαφρώς πιο ακριβείς απαντήσεις, σύμφωνα με την εφημερίδα.
Είναι εντυπωσιακό πως ερευνητές ανά τον κόσμο, με λίγα δολάρια, μπορούν να δημιουργήσουν υλοποιήσεις τεχνητής νοημοσύνης που ανταγωνίζονται τις Big Tech. Χρησιμοποιούν βέβαια την διαδικασία της απόσταξης, για να πάρουν τα δεδομένα από τις Big Tech για την εκπαίδευση των μοντέλων τους, καθώς δεν έχουν την πρόσβαση που έχουν αυτές για να κάνουν crawl όλο το διαδίκτυο, κλέβοντας την πνευματική ιδιοκτησία όλων των ιστοσελίδων του διαδικτύου.
Η OpenAI έχει αρχίσει την γκρίνια για τα άλλα μοντέλα τεχνητής νοημοσύνης που της “κλέβουν” τα δεδομένα, που έχει κλέψει από το διαδίκτυο, για να εκπαιδεύσει τα μοντέλα της που κόστισαν πολλά δισεκατομμύρια.
Χειμωνιάτικες προσφορές Xiaomi σε smartphones και προϊόντα οικοσυστήματος
Από την άλλη, η απόσταξη των δεδομένα δεν είναι αυτό που φέρνει την καινοτομία στην τεχνητή νοημοσύνη, απλά παρέχει τα δεδομένα για να εκπαιδευτεί, ενώ επιτρέπει και την οικονομική αναπαραγωγή υφιστάμενων τεχνολογιών. Οι βελτιώσεις όμως που έκαναν τόσο οι ερευνητές του s1 όσο και η ομάδα πίσω από το DeepSeek, είναι η πραγματική πρόοδος στην τεχνητή νοημοσύνη, πόσο μάλλον όταν διαθέτουν τις υλοποιήσεις τους δωρεάν για χρήση από όποιον επιθυμεί.
Το σημαντικό πρόβλημα όμως είναι πως αυτά τα δεδομένα που χρησιμοποιούν όλες οι μεγάλες εταιρίες παραγωγής τεχνητής νοημοσύνης, είναι προϊόν λογοκλοπής και κανείς δεν κάνει κάτι για αυτό.
Για την ιστορία, οι ερευνητές νοίκιασαν servers με 16 μόνο Nvidia H100 GPUs για $20 και χρειάστηκαν λιγότερο από μισή ώρα για να τελειώσει η εκπαίδευσή του μοντέλου τους. Αυτό δείχνει πως η ανάπτυξη μοντέλων τεχνητής νοημοσύνης δεν έχει να κάνει πάντα με το πόσα χρήματα έχει η κάθε εταιρία για να “πετάξει”, κάτι που κάνει τους επενδυτές στην τεχνητή νοημοσύνη να αμφισβητούν τις επιλογές τους. Οι Big Tech έχουν ήδη επενδύσει εκατοντάδες δισεκατομμύρια σε υποδομές και τώρα θέλουν να αυξήσουν τις επενδύσεις τους.
Η μελέτη δημοσιεύθηκε στο ArXiv.
Ακολουθήστε το Techmaniacs.gr στο Google News για να διαβάζετε πρώτοι όλα τα τεχνολογικά νέα. Ένας ακόμα τρόπος να μαθαίνετε τα πάντα πρώτοι είναι να προσθέσετε το Techmaniacs.gr στον RSS feeder σας χρησιμοποιώντας τον σύνδεσμο: https://techmaniacs.gr/feed/.






